
一般的じゃなくて、IT、コンピューター分野。アルゴリズムとデータ構造について、流れ図(フローチャート)からわかりやすく!を心がけて説明していきます。
アルゴリズムという言葉は、ITやコンピューターに限らず、広くさまざまな場面で使われています。 アルゴリズムとは、一般的には「問題を解決する手順」という説明になります。
ITやコンピューター分野におけるアルゴリズムは、コンピュータで問題を処理するためにプログラムとして表現するのに向いている解決法です。
例をあげると、グラフ理論、オペレーションズリサーチ、数値計算、データ構造の操作、整列、数式処理、言語処理などです。
アルゴリズムといえば、まずは流れ図(フローチャート)ですね。流れ図について説明していきます。
流れ図は、変数に実際の値を代入して処理後の値を確かめるのに用います。
次の流れ図において、
①→②→③→⑤→②→③→④→②→⑥
の順に実行させるために、①においてmとnに与えるべき初期値aとbの関係はどれかを確かめることにします。
a、bはともに正の整数です。
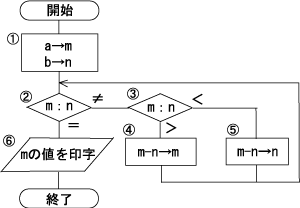
初期値の候補
[ア]a=2b、[イ]2a=b、[ウ]2a=3b、[エ]3a=2b
| 順番 | 設問 | 選択肢 |
| ① | m(a),n(b) | [ア]a=2b(○) [イ]2a=b(○) [ウ]2a=3b(○) [エ]3a=2b(○) |
|---|---|---|
| ② | m(a)≠n(b) | [ア]a=2b(○) [イ]2a=b(○) [ウ]2a=3b(○) [エ]3a=2b(○) |
| ③ | m(a)<n(b) | [イ]2a=b(○) [エ]3a=2b(○) |
| ⑤ | n(b)-m(a)→n(b-a) | [イ]2a=b(○) [エ]3a=2b(○) |
| ② | m(a)≠n(b-a) | [エ]3a=2b(○) |
| ③ | m(a)>n(b-a) | [エ]3a=2b(○) |
| ④ | m(a)-n(b-a)→m(2a-b) | [エ]3a=2b(○) |
| ⑥ | mの値を印字 | [エ]3a=2b(○) |
[エ]3a=2bが①→②→③→⑤→②→③→④→②→⑥の順に実行させる初期値であることが分かりました。
次の流れ図は、シフト演算と加算の繰り返しによって2進数の乗算を行う手順を表したものです。 ここで、乗算と被乗算は符号なしの16ビットで表されます。 X、Y、Zは32ビットのレジスタであり、けた送りには論理シフトを用いる。
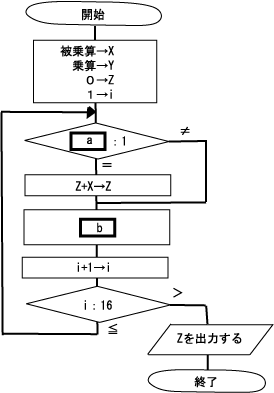
ここで、a、bに着目してみます。 Xは被乗数、Yは乗数、Zは乗算結果であることに注意して流れ図を見ます。
線形探索は、配列の先頭から順番に目的のデータが見つかるまで探索する方法です。
p個のデータを線形探索するときの平均探索回数はp/2です。
たとえば、相異なるn個のデータが昇順に整列された表があり、 この表を1ブロックm個に分割し、各ブロックの最後尾のデータだけ線形探索することによって、 目的のデータの存在するブロックを探し出し、 次に該当ブロック内を線形探索して目的のデータを探し出すという探索のとき、 このときの平均探索回数は次のようになります。
なお、m<nとし、目的のデータは必ず表の中に存在するものとします。
nをm個づつブロックに分けて、その最後尾だけを探索することは ブロック数分の線形探索を行うことなので検索回数は(n/m)/2回となります。
また、ブロック内の検索はm個の線形探索なのでm/2となります。
よって、平均探索回数はm/2+(n/m)/2回になります。
2分探索は、探索されるデータが昇順、または降順に整列している場合に使用できます。 探索データの中央の値と目的のデータを比較し、一致しなければ、中央の値の上下どちらにあるかを判断し、 探索データを半分に絞り込み、比較を続けていく方法です。
たとえば、昇順に整列済の配列要素A(1)、A(2)、…A(n)から、A(m)=kとなる配列要素A(m)の添字mを 2分探索法によって見つける処理を図に示すと次のようになります。
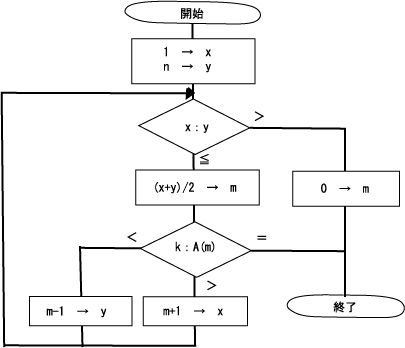
この流れ図を見ても分かるように、(x+y)/2→mで中央値を求めて解の選択の幅を狭めていることが分かります。 なお、終了時点でm=0の場合、A(m)=kとなる要素は存在しません。
キューとは、1次元配列に格納されたデータの一方からデータを格納し、 他方の端からデータを取り出すデータ構造のことです。 このようなデータの出し入れをFIFO(First-In First-Out:先入れ先出し)と呼びます。
また、スタックとは、1次元配列に格納された後から入れたデータを 先に取り出すデータ構造のことをいいます。 このようなデータの出し入れをLIFO(Last-In First-Out:後入れ先出し)と呼びます。
なお、
データyをスタックに挿入することをpush(y),
スタックからデータを取り出すことをpop(),
データyをキューに挿入することをenq(y),
キューからデータを取り出すことをdeq(),
とそれぞれ表わします。
たとえば、
push(a)
push(b)
enq(pop())
enq(c)
push(d)
push(deq())
x←pop()
としたとき、次のような処理がおこなわれます。
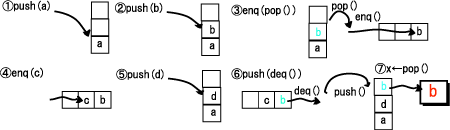
よって、変数xにはbが入ります。
ITスキルを体系的に把握するコンテンツとしてzealseedsのITスキル体系をまとめています。
スポンサーリンク
サイト内のページ
 言語
言語
C・C++
/HTML
/Java
/JavaScript
/PHP
/シェルスクリプト
開発環境
Ant
/Burp
/Eclipse
/Fiddler
/gcc
/gdb
/Git
/g++
/JDK
/JMeter
/JUnit
/Teraterm
/ZAP
技術・仕様
Ajax
/CORBA
/Jakarta EE(旧称J2EE、Java EE)
/JNI
ライブラリ/Framework/CMS
bootstrap
/jQuery
/FuelPHP
/Lucene
/MyBatis
/Seasar2
/Spring
/Struts
/WordPress
Web API
Google Maps
ITインフラOSとミドルウェア
Linux
/Windows
/シェル
ActiveMQ
/Tomcat
/MariaDB
/MySQL
/Nagios
/Redis
/Solr
ITインフラセキュリティ
公開サーバーのセキュリティ
SI
ホームページの作り方
スポンサーリンク
IPアドレス確認ツール
あなたのグローバルIPアドレスは以下です。
216.73.216.228
HTMLの表示色確認ツール
パスワード生成ツール
文字数のプルダウンを選択して、取得ボタンを押すと「a~z、A~Z、0~9」の文字を ランダムに組み合わせた文字列が表示されます。
ここに生成されます。
スポンサーリンク
Copyright (C) 2007-2024 zealseeds. All Rights Reserved.